728x90

NumPy
- Python의 Numarray와 Numeric 패키지를 계승한 패키지
- 상당부분 C로 작성되어 대규모 데이터를 처리할 때에도 실행 속도가 빠른 것이 특징
- Scipy(사이파이), Pandas(판다스), matplotlib(패트플롯라이브러리) 등의 패키지로 확장됨
- NumPy의 기본 객체는 '다차원 동질성 배열 (homogeneous multidimensional array)'
스칼라 자료형

- 기본 자료형은 float_
- 위 그림은 자료형의 계층 구조를 나타냄. numpy.generic, numpy.signedinteger 등으로 사용 가능
- inexact는 부동소수점을 사용하여 정확한 값을 나타내지 않음
| 자료형 (numpy.scalar) | 코드 | alias | C에서의 자료형 |
| byte | b | int8 | char |
| short | h | int16 | short |
| intc | i | int32 | int |
| int_ | l (소문자 L) | int64, intp | long |
| longlong | q | - | long long |
| ubyte | B | uint8 | unsigned char |
| ushort | H | uint16 | unsigned short |
| uintc | I (대문자 i) | uint32 | unsigned int |
| uint | L | uint64, uintp | unsigned long |
| ulonglong | Q | - | unsigned long long |
| half | e | float16 | - |
| single | f | float32 | float |
| double | d | float_, float64 | double |
| longdouble | g | longfloat, float128 | long double |
| csingle | F | singlecomplex, complex64 | - |
| cdouble | D | cfloat, complex_, complex128 | - |
| clongdouble | G | clongfloat, longcomplex, complex256 | - |
| bool_ | ? | bool8 | - |
| datetime64 | M | - | - |
| timedelta64 | m | - | - |
| object | O | - | - |
| bytes | S | string_ | - |
| str_ | U | unicode_ | - |
| void | V | - | - |
ndarray (alias : array)
- 동질성 배열이므로 같은 종류의 데이터를 연속으로 저장한다. (C언어의 배열과 유사)
- ndarray는 n차원 배열. 역시 동일한 자료형의 데이터만 처리
- 백터화 연산(vectorized operation) 을 지원하여 모든 원소에 명령을 병렬적으로 연산
- 배열과 배열 간 수학적 연산 가능
- 차원을 axes라 부름
- 리스트에서 a[i][j]로 접근했다면 여기서는 a[i, j]로 접근
- numpy.array(data)로 array 생성. range 사용 가능
| 속성 (ndarray.attributes) | 설명 |
| flags | array의 memory layout에 대한 정보 |
| shape | array의 차원의 길이(?)를 Tuple로 반환 |
| strides | array의 각 차원에 접근하려면 몇 바이트를 이동해야 하는지를 튜플로 반환 |
| ndim | array 차원의 개수 |
| data | array의 데이터 시작점을 가르키는 파이썬 버퍼 객체 |
| size | array에 포함된 요소의 개수 |
| itemsize | array 요소 한개의 길이를 bytes로 반환 |
| nbytes | array의 요소들이 차지하고 있는 총 byte |
| base | 참조되었을 경우의 base 객체 (y = x, y.base 하면 x 반환) |
| dtype | array 요소의 자료형 |
| T | 전치된 array 반환 |
| real | array 요소들의 실수부분으로만 array 반환 |
| imag | array 요소들의 허수부분으로만 array 반환 |
| flat | 1차원 접근 (길이가 3인 2차원 배열 x에 x.flat[3]을 하면 (2,1) 값을 반환) |
| 변환 메서드 | 인자 | 설명 |
| item | (*args) | 하나의 요소를 파이썬 스칼라로 복사하여 반환 |
| tolist | () | array를 파이썬 기본 자료형으로 바꾼 list로 반환 |
| itemset | (*args) | 요소 값 설정(첫 인자는 flat형식이거나 좌표 튜플로 전달) |
| tostring | ([order]) | tobytes의 alias (str로 돌려주지 않음) |
| tobytes | ([order]) | 파이썬 raw 데이터로 변환(예: b'\x00\x01\x02') |
| tofile | (fid[, sep, format]) | arrayt를 text나 binary로 fid에 작성 |
| dump | (file) | file에 array의 pickle을 dump |
| dumps | () | array의 pickle을 string으로 반환 |
| astype | (dtype[, order, casting, ...]) | array를 dtype으로 복사 |
| byteswap | ([inplace]) | array 요소의 byte를 swap |
| copy | ([order]) | array의 복사본을 반환 |
| view | ([dtype][, type]) | dtype으로 array를 표시 (여러 용법 존재) |
| getfield | (dtype[, offset]) | dtype으로 field를 반환 |
| setflags | ([write, align, uic]) | array의 flag 설정(WRITEABLE, ALIGNED 등..) |
| fill | (value) | value로 array를 채움 |
| 구조 변형 메서드 | 인자 | 설명 |
| reshape | (shape[,order]) | 같은 데이터를 새로운 shape으로 반환(shape은 튜플) |
| resize | (new_shape[, refcheck]) | 모양이랑 사이즈를 바꿈 |
| transpose | (*axes) | 전치된 array를 반환 |
| swapaxes | (axis1, axis2) | axis1과 axis2가 바뀐 형태로 data 표시 |
| flatten | ([order]) | 1차원으로 바꾼 array의 복사본 반환 |
| ravel | ([order]) | 1차원으로 바꾼 array 반환 |
| squeeze | ([axis]) | 길이가 1인 차원을 제거 |
| 아이템 선택 및 변형 메서드 | 인자 | 설명 |
| take | (indices[, axis, out, mode]) | indices(index 배열)의 요소들로 array를 만들어 반환 |
| put | (indices, values[, mode]) | indices[]의 요소에 values[] 대입 |
| repeat | (repeats[, axis]) | array의 요소들은 repeats 만큼 반복 (1차원 리스트) |
| choose | (choices[, out, mode]) | choices에 해당하는 요소로 array를 만들어 반환 |
| sort | ([axis, kind, order]) | axis가 주어지면 해당 axis에 대해 정렬 |
| argsort | ([axis, kind, order]) | 정렬된 상태의 indices(좌표) 반환 |
| partition | (kth[, axis, kind, order]) | kth번째 정렬 위치를 기준으로 대소비교로 대충 정렬(?) |
| argpartition | (kth[, axis, kind, order]) | partition과 유사. indices 반환 |
| searchsorted | (v[, side, sorter]) | v의 요소들이 배치될 위치를 indices로 반환 |
| nonzero | () | 0 이 아닌 요소들의 indices 반환 |
| compress | (condition[, axis, out]) | axis와 condition으로 잘린 array를 반환 |
| diagonal | ([offset, axis1, axis2]) | 특정 대각선을 반환 |
| 계산 메서드 | 인자 | 설명 |
| max | ([axis, out, keepdims, initial, ...]) | 주어진 axis에서의 최댓값 반환 |
| argmax | ([axis, out]) | 주어진 axis에서의 최댓값의 indices 반환 |
| min | ([axis, out, keepdims, initial, ...]) | 주어진 axis에서의 최솟값 반환 |
| argmin | ([axis, out]) | 주어진 axis에서의 최솟값의 indices 반환 |
| ptp | ([axis, out, keepdims]) | axis 별로 max - min 값의 array 반환 |
| clip | ([min, max, out]) | 요소의 값이 min과 max로 제한된 array 반환 |
| conj | () | 모든 요소의 켤레복소수 반환 |
| round | ([decimals, out]) | decimals 기준으로 모든 요소를 반올림한 array 반환 |
| trace | ([offset, axis1, axis2, dtype, out]) | 대각선의 합을 반환 |
| sum | ([axis, dtype, out, keepdims, ...]) | axis의 합 반환 |
| cumsum | ([axis, dtype, out]) | axis의 누적 합 반환 |
| mean | ([axis, dtype, out, keepdims, where]) | axis의 평균 반환 |
| var | ([axis, dtype, out, ddof, ...]) | axis의 분산 반환 |
| std | ([axis, dtype, out, ddof, ...]) | axis의 표준편차 반환 |
| prod | ([axis, dtype, out, keepdims, ...]) | axis의 곱 반환 |
| cumprod | ([axis, dtype, out]) | axis의 누적 곱 반환 |
| all | ([axis, out, keepdims, where]) | 모든 요소가 True면 True 반환 |
| any | ([axis, out, keepdims, where]) | 한 요소라도 True면 True 반환 |
array 생성 방법
- From shape or value
| 방법 | 인자 | 설명 |
| empty | (shape[, dtype, order, like]) | shape 모양의 array 반환. 타입은 dtype |
| empty_like | (prototype[, dtype, order, subok, ...]) | prototype과 같은 모양의 array 반환 |
| eye | (N[, M, k, dtype, order, like]) | 대각선은 1, 나머지는 0인 array 반환. k는 대각선 시작 위치 |
| identity | (n[, dtype, like]) | n * n의 단위행렬 반환 |
| ones | (shape[, dtype, order, like]) | 1로 채워진 shape 모양의 array 반환 |
| ones_like | (a[, dtype, order, subok, shape]) | 1로 채워진 a와 같은 모양의 array 반환 |
| zeros | (shape[, dtype, order, like]) | 0으로 채워진 shape 모양의 array 반환 |
| zeros_like | (a[, dtype, order, subok, shape]) | 0으로 채워진 a와 같은 모양의 array 반환 |
| full | (shape, fill_value[, dtype, order, like]) | fill_value로 채워진 shape 모양의 array 반환 |
| full_like | (a, fill_value[, dtype, order, ...]) | fill_value로 채워진 a와 같은 모양의 array 반환 |
- From existing data
| 방법 | 인자 | 설명 |
| array | (object[, dtype, copy, order, subok, ...]) | object로 array 생성하여 반환 |
| asarray | (a[, dtype, order, like]) | a를 주어진 dtype, order, like로 array 생성(변환)하여 반환 |
| asanyarray | (a[, dtype, order, like]) | a를 ndarray로 변환하여 반환(ndarray면 그대로 반환) |
| ascontiguousarray | (a[, dtype, like]) | C order의 contiguous array 를 만들어 반환 |
| asmatrix | (data[, dtype]) | data를 행렬로 해석하여 반환 |
| copy | (a[, order, subok]) | a의 복사본을 만들어 반환 |
| frombuffer | (buffer[, dtype, count, offset, like]) | buffer를 1차원 array로 해석하여 반환 |
| fromfile | (file[, dtype, count, sep, offset, like]) | 텍스트나 binary 파일에서부터 array를 생성하여 반환 |
| fromfunction | (function, shape, *[, dtype, like]) | function을 이용하여 array를 만들어 반환 |
| fromiter | (iter, dtype[, count, like]) | iterable 객체로부터 1차원 array를 만들어 반환 |
| fromstring | (string[, dtype, count, like]) | string의 텍스트 데이터로 1차원 array를 만들어 반환 |
| loadtxt | (fname[, dtype, comments, delimiter, ...]) | fname의 텍스트 파일로부터 데이터를 불러옴 |
- Creating record array (numpy.rec은 numpy.core.records의 preferred alias)
| 방법 | 인자 | 설명 |
| rec.array | (obj[, dtype, shape, ...]) | 다양한 종류의 객체인 obj로부터 record 생성 |
| rec.fromarray | (arrayList[, dtype, ...]) | 1차원 List의 list인 arrayList로부터 record 생성 |
| rec.fromrecords | (recList[, dtype, ...]) | 텍스트 형태의 record의 list에서 recarray 생성 |
| rec.fromstring | (datastring[, dtype, ...]) | binary 데이터로부터 record array 생성 |
| rec.fromfile | (fd[, dtype, shape, ...]) | binary 파일 데이터인 fd로부터 array 생성 |
- Creating character arrays (numpy.char은 numpy.core.defchararray의 preferred alias)
| 방법 | 인자 | 설명 |
| char.array | (obj[, itemsize, ...]) | chararray 생성 |
| char.asarray | (onj[, itemsize, ...]) | obj를 chararray로 변환. 필요할 경우에만 데이터 복사 |
- Numerical ranges
| 방법 | 인자 | 설명 |
| arange | ([start,] stop[, step,][, dtype, like]) | 주어진 step 만큼 떨어진 값의 array 생성 |
| linspace | (start, stop[, num, endpoint, ...]) | 주어진 step 만큼 차이나는 숫자의 array 생성 (range와 유사) |
| logspace | (start, stop[, num, endpoint, base, ...]) | log scale에서 일정하게 차이나는 숫자로 array 생성 |
| geomspace | (start, stop[, num, endpoint, ...]) | logspace와 같으나 등비수열(geometric progression) 사용 |
| meshgrid | (*xi[, copy, sparse, indexing]) | 좌표 벡터로부터 좌표 행렬을 반환 |
| mgrid | - | 빽빽한(dense) 다차원의 meshgrid 반환 |
| ogrid | - | 열려있는(open) 다차원의 meshgrid 반환 |
- Building matrices
| 방법 | 인자 | 설명 |
| diag | (v[, k]) | 대각선을 추출(Extract)하거나 대각행렬을 생성 (v에 다름) |
| diagflat | (v[, k]) | 1차원 v가 대각인 2차원 array 반환 |
| tri | (N[, M, k, dtype, like]) | 대각 밑으로는 1, 나머지는 0인 array 반환 |
| tril | (m[, k]) | m의 Lower triangle 반환 (대각선 아래의 값 외에는 0) |
| triu | (m[, k]) | m의 Upper triangle 반환 (대각선 위의 값 외에는 0) |
| vander | (x[, N, increasing]) | 방데르몽드 행렬 반환 |
- The Matrix class
| 방법 | 인자 | 설명 |
| mat | (data[, dtype]) | data를 행렬로 해석 |
| bmat | (obj[, ldict, gdict]) | string, nested sequence, array로 부터 행렬 객체 생성 |
배열의 연산
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([[10, 20, 30], [40, 50, 60]])
print(a + b)
print(a - b)
print(a * b)
print(a / b)
print(a == 2)
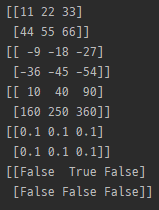
- 사칙연산 및 비교는 은 배열의 값끼리.
상수
| 상수 (numpy.constants) | 설명 |
| Inf | 양의 무한 |
| Infinity | 양의 무한 |
| NAN | Not a Number |
| NINF | 음의 무한 |
| NZERO | 음의 0 |
| NaN | Not a Number |
| PINF | 양의 무한 |
| PZERO | 양의 0 |
| e | 자연상수 (e = 2.71828182845904523536028747135266249775724709369995...) |
| euler_gamma | 오일러 감마 (γ = 0.5772156649015328606065120900824024310421...) |
| inf | 양의 무한 |
| infty | 양의 무한 |
| nan | Not a Number |
| newaxis | None의 alias |
| pi | 원주율 (pi = 3.1415926535897932384626433...) |
참조
- NumPy 공식문서
반응형