
함수 정리
| 함수 | 파라미터 | 설명 |
| accumulate | iterable[, func, *, initial=None] | - 누적 합계를 반환하는 이터레이터를 반환 - func에 합계 대신 다른 함수를 넣을 수 있음 |
| chain | *iterables | - 여러 iterable을 연달아 반환 |
| chain.from_iterable | iterable | - iterable을 여러개 받는 대신, iterable의 요소를 iterable로 |
| combinations | iterable, r | - 조합 - 튜플 형태로 반환 |
| combinations_with_replacement | iterable, r | - 중복조합 - 튜플 형태로 반환 |
| compress | data, selectors | - selectors가 true인 인덱스의 data만 반환 - 둘다 iterable이며, 짧은 것 기준으로 동작 |
| count | start=0, step=1 | - start부터 step 만큼 더하면서 요소를 반복 - float도 가능하지만 지양 |
| cycle | iterable | - iterable을 계속 반복하여 반환 - 무한히 반복 |
| dropwhile | predicate, iterable | - predicate가 false인 요소부터 요소를 반환 - takewhile의 반대 |
| filterfalse | predicate, iterable | - predicate가 false인 요소만 반환 - predicate가 None이면 거짓인 요소를 반환 |
| groupby | iterable, key=None | - (key, iterator) 형태의 튜플을 반환하는 iterator 반환 - key 값을 기준으로 group된 요소를 반환하는 이터레이터 |
| islice | iterable, stop | - stop 인덱스까지의 요소 반환 (stop을 안주면 끝까지) |
| iterable, start, stop[, step] | - start에서부터 stop까지 step 만큼 건너뛰면서 | |
| pairwise | iterable | - 연속하는 두개의 요소를 튜플로 묶어줌 - '연속하는 두개'의 모든 가짓수 반환 |
| permutations | iterable, r=None | - 순열 (값이 중복되어도 위치로 고유성 다룸) - 튜플 형태로 반환 |
| product | *iterables, repeat=1 | - 여러 iterable의 데카르트 곱. (repeat 만큼 반복) - iterable을 하나만 줄 경우 reapeat을 r로 하는 중복순열 |
| repeat | object[, times] | - object를 times 번 만큼 반복 - times를 명시하지 않으면 무한으로 반복 |
| starmap | function, iterable | - iterable의 tuple을 이용해 func 계산 - 이미 zip 되어 있는 iterable에 func을 적용 |
| takewhile | predicate, iterable | - predicate가 false이기 전까지 요소 반환 - dropwhile의 반대 |
| tee | iterable, n=2 | - 튜플 형태로 같은 이터레이터를 n개 만큼 반환 - thread-safe하지 않아서 주의를 요함 |
| zip_longest | *iterables, fillvalue=None | - 가장 긴 요소를 기준으로 반환하는 zip() - 빈 공간을 fillvalue로 채움 |
accumulate
import itertools
myList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(type(itertools.accumulate(myList)))
print(itertools.accumulate(myList))
print()
print(list(itertools.accumulate(myList)))
print(list(itertools.accumulate(myList, initial=0)))
print()
print(list(itertools.accumulate(myList, max)))
print(list(itertools.accumulate(myList, max, initial=0)))
print()
print(list(itertools.accumulate(myList, lambda x, y: x * y)))
print(list(itertools.accumulate(myList, lambda x, y: x * y, initial=1)))
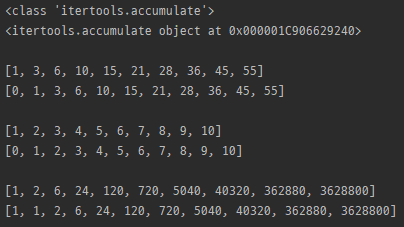
- 기본적으로 결과값의 길이는 같으나, initial을 주면 하나가 더 늘어남
- 첫번째 인자는 그대로 전달
chain
import itertools
myList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'Hello', 'World', '!']
myString = 'Hello World!'
print(type(itertools.chain(myList)))
print(itertools.chain(myList))
print()
print(list(itertools.chain(myList)))
print(list(itertools.chain(myString)))

- 요소를 하나씩 돌려주는 이터레이터 반환
- 여러 iterable을 단일 iterable 처럼 사용할때 사용
chain.from_iterable
import itertools
myList = ['Hello', 'World', '!']
myString = 'Hello World!'
print(type(itertools.chain.from_iterable(myList)))
print(itertools.chain.from_iterable(myList))
print()
print(list(itertools.chain.from_iterable(myList)))
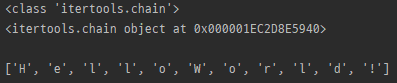
- iterable의 요소를 iterable로 받아서 chain과 같이 처리함
combinations
import itertools
myList = [1, 2, 3, 4, 5]
print(type(itertools.combinations(myList, 2)))
print(itertools.combinations(myList, 2))
print()
print(list(itertools.combinations(myList, 2)))

- nCr 에서 n은 요소의 개수, r은 인자로 넘겨줌
- 가능한 모든 조합의 tuple을 반환하는 이터레이터 반환
- 요소는 값이 아니라 위치로 고유성을 다룸 (값의 중복 허용)
combinations_with_replacement
import itertools
myList = [1, 2, 3, 1]
print(type(itertools.combinations_with_replacement(myList, 2)))
print(itertools.combinations_with_replacement(myList, 2))
print()
print(list(itertools.combinations(myList, 2)))
print(list(itertools.combinations_with_replacement(myList, 2)))
print()
print(list(itertools.combinations(myList, 3)))
print(list(itertools.combinations_with_replacement(myList, 3)))
print()

- 중복 조합
- 개별 요소를 두번 이상 반복 (r = 2의 경우 요소 내가 두번 있는 놈 추가, r = 3 일 경우 내가 두번, 내가 세번 있는 놈 추가)
compress
import itertools
myList1 = [0, 1, 2, 3, 4, 5, 6, 7]
myList2 = [1, 0, True, False, 'string', '']
print(type(itertools.compress(myList1, myList2)))
print(itertools.compress(myList1, myList2))
print()
print(list(itertools.compress(myList1, myList2)))
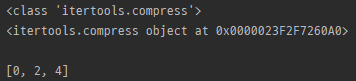
- 해당 index의 selectors 요소가 True 인 놈들만 반환하는 iterator 반환
- 길이가 다르면 짧은 놈 기준
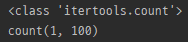
count
import itertools
print(type(itertools.count(1, 100)))
print(itertools.count(1, 100))
print()
- start부터 step 간격으로 무한히 증가하는 요소를 반환
- 연속적인 데이터를 다루기 위한 map()에 대한 인자나 시퀀스 번호를 추가하기 위한 zip()과 함께 사용됨
- int 대신에 float도 작동은 하나, 정확도를 위해 (start + step * i for i in count()) 등을 이용하길 권장
- c언어 스러운 for문을 돌리기도 좋을 듯
cycle
import itertools
myList = [1, 2, 3]
print(type(itertools.cycle(myList)))
print(itertools.cycle(myList))

- iterable의 요소를 반복하며 계속 반환하는 iterator 반환
dropwhile
import itertools
myList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(type(itertools.dropwhile(lambda x: x % 5, myList)))
print(itertools.dropwhile(lambda x: x % 5, myList))
print()
print(list(itertools.dropwhile(lambda x: x % 5, myList)))
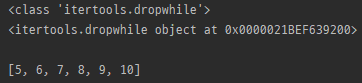
- predicate가 거짓인 경우를 만나기 전까지 모든 요소를 반환
filterfalse
import itertools
myList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(type(itertools.filterfalse(lambda x: x % 2, myList)))
print(itertools.filterfalse(lambda x: x % 2, myList))
print()
print(list(itertools.filterfalse(lambda x: x % 2, myList)))
print(list(itertools.filterfalse(None, myList)))

- predicate가 False 인 요소만 반환하는 iterator 반환
- predicate가 None인 경우 거짓인 항목을 반환
groupby
import itertools
myString = 'abbcccddddaaa'
myList = [('Europe', 'Manchester'),
('America', 'NewYork'),
('Asia', 'Seoul'),
('Asia', 'Tokyo'),
('America', 'Chicago'),
('America', 'Seattle'),
('Europe', 'London'),
('Asia', 'Beijing'),
('Europe', 'Paris'),
]
print(type(itertools.groupby(myList)))
print(itertools.groupby(myList))
print()
print(list(itertools.groupby(myString)))
print()
for item in itertools.groupby(myString):
print(list(item[1]))
print()
# 예시
category = {}
for key, group in itertools.groupby(sorted(myList), lambda x: x[0]):
listg = [x[1] for x in list(group)]
category[key] = listg
print(category)
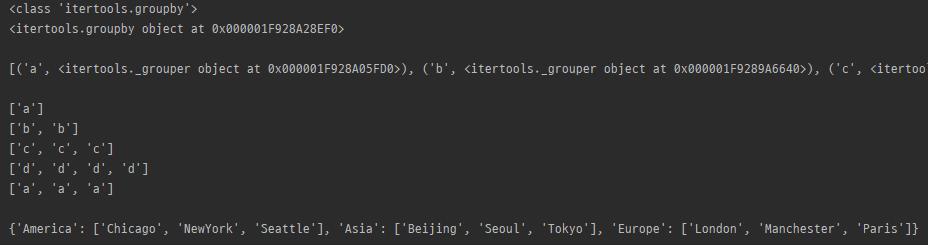
- key 값을 기준으로 값들을 묶어서 (key, iterator) 형태의 튜플 변환
- 판다스의 groupby와 다른놈 (비슷하긴 함)
- SQL의 GROUP BY와는 다름
islice
import itertools
myString = '123456789'
print(type(itertools.islice(myString, None)))
print(itertools.islice(myString, None))
print()
print(list(itertools.islice(myString, None)))
print(list(itertools.islice(myString, 2)))
print(list(itertools.islice(myString, 3, None, 2)))

- start 부터 stop 까지 step으로 건너 뛰면서 요소 하나씩 반환하는 iterator 반환
- stop이 None이면 끝까지
pairwise
import itertools
myString = '123456789'
print(type(itertools.pairwise(myString)))
print(itertools.pairwise(myString))
print()
print(list(itertools.pairwise(myString)))

- 가능한 연속하는 두개의 요소를 묶어서 반환.
permutations
import itertools
myString = 'abcd'
print(type(itertools.permutations(myString)))
print(itertools.permutations(myString))
print()
print(list(itertools.permutations(myString, 2)))

- 순열
- nPr 에서 n은 요소의 개수, r은 파라미터로 전달
- 값이 아니라 순서로 고유성을 다룸
- None은 최대 값으로
product
import itertools
myString = 'abc'
myList = [1, 2]
print(type(itertools.product(myString)))
print(itertools.product(myString))
print()
print(list(itertools.product(myString, repeat=2)))
print(list(itertools.product(myString, myList)))
print(list(itertools.product(myString, myList, repeat=2)))

- iterable을 하나만 주면 중복순열
- 여러개 주면 데카르트 곱
repeat
import itertools
print(type(itertools.repeat('a')))
print(itertools.repeat('a'))
print()
print(list(itertools.repeat('a', 10)))

- times를 주지 않으면 영원히 반복
starmap
import itertools
myList = [(2,5), (3,2), (10,3)]
print(type(itertools.starmap(pow, myList)))
print(itertools.starmap(pow, myList))
print()
print(list(itertools.starmap(pow, myList)))
print()
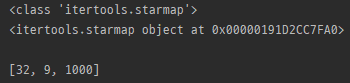
- iterable에서 얻은 인자를 사용하여 함수를 계산
- 인자 매개 변수가 이미 튜플일때 (미리 zip 일때) map()대신 계산
takewhile
import itertools
myList = [1, 2, 3, 2, 1]
print(type(itertools.takewhile(lambda x : x < 3, myList)))
print(itertools.takewhile(lambda x : x < 3, myList))
print()
print(list(itertools.takewhile(lambda x : x < 3, myList)))
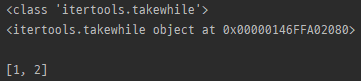
- predicate가 true일 동안만 요소를 반환 (dropwhile의 반대)
- 첫 false 이후 중단
tee
import itertools
myList = [1, 2, 3]
print(type(itertools.tee(myList)))
print(itertools.tee(myList))
print()
t1, t2, t3 = itertools.tee(myList, 3)
print(list(t1))
print(list(t2))
print(list(t3))

- 튜플 형태로 같은 이터레이터를 n개 만큼 반환
- thread-safe하지 않아서 이터러블과 tee 객체를 동시에 쓰기 어려움 (공식 문서 참조)
zip_longest
import itertools
myList1 = [1, 2, 3]
myList2 = [1, 2, 3, 4, 5]
print(type(itertools.zip_longest(myList1, myList2)))
print(itertools.zip_longest(myList1, myList2))
print()
print(list(itertools.zip_longest(myList1, myList2)))
print(list(itertools.zip_longest(myList1, myList2, fillvalue=0)))

- zip()이랑 같지만 가장 긴 iterable 기준으로 맞춤 (zip은 가장 짧은 iterable을 기준으로 남는건 버림)
- 비어있는 (짧은 iterable에서 범위 밖)은 fillvalue로 채워짐
참조
- 파이썬 공식 문서
- PythonEngine 블로그
- aonee 님의 블로그
'Languages > Python' 카테고리의 다른 글
| [파이썬 101] string 외장 및 내장 모듈 (문자열) (0) | 2022.06.22 |
|---|---|
| [파이썬 라이브러리] heapq (0) | 2022.06.03 |
| [파이썬 101] all과 any (0) | 2022.06.03 |
| [파이썬 101] List, Set, Dictionary 연산과 메서드의 시간복잡도 (0) | 2022.06.03 |
| [파이썬 라이브러리] Collections 모듈의 deque (데크, 덱, 디큐, 데큐) (0) | 2022.06.03 |



