
플래그
| 플래그 | 설명 |
| re.A re.ASCII |
유니코드 대신 ASCII 전용 일치 수행 |
| re.U re.UNICODE |
유니코드 일치. (파이썬3에서는 default이므로 필요 없음) |
| re.DEBUG | 컴파일된 정규식에 대한 디버그 정보 표시 |
| re.I re.IGNORECASE |
대소문자를 구분하지 않는 일치 |
| re.L re.LOCALE |
특정 일치를 로케일에 의존하도록 함 (권장 X) |
| re.M re.MULTILINE |
'^'와 '$'에서 기준을 줄바꿈 단위로 일치 (문자열 시작, 문자열 끝, 개행 전후) |
| re.S re.DOTALL |
'.' 가 줄넘김을 포함하여 모든 문자와 일치하도록 함 (default : 개행을 제외한 모든 문자) |
| re.X re.VERBOSE |
채턴 내 공백 무시 (주석으로 더 직관적인 코드를 작성할때 사용) |
- 플래그 상수는 enum.IntFlag의 서브 클래스인 RegexFlag의 인스턴스
함수
| 함수 | 인자 | 설명 | 반환 (일치) | 반환 (일치X) |
| compile | pattern, flag=0 | 정규식 패턴을 정규식 객체로 컴파일 | re.Pattern | |
| search | pattern, string, flags=0 | 첫번째 일치 위치를 찾고 일치 객체 반환 | re.Match | None |
| match | pattern, string, flags=0 | 처음에서 0개 이상의 문자 일치시 반환 | re.Match | None |
| fullmatch | pattern, string, flags=0 | string 전체가 일치시 반환 | re.Match | None |
| split | pattern, string, maxsplit=0, flags=0 | 일치를 기준으로 잘라서 리스트 반환 | list [string] | |
| findall | pattern, string, flags=0 | 일치되는 모든 문자열을 리스트로 반환 | list [string or tuple(string)] | |
| finditer | pattern, string, flags=0 | findall과 같지만 iterator 반환 | callable_iterator | |
| sub | pattern, repl, string, count=0, flags=0 | 일치된걸 repl(문자열이나 함수)로 대체 | str | |
| subn | pattern, repl, string, count=0, flags=0 | sub()와 같지만 (문자열, sub 개수) 반환 | tuple(str, number) | |
| escape | pattern | 특수문자를 이스케이프 처리하여 패턴 반환 | str | |
| purge | x | 정규식 캐시를 지움 | X | |
re.compile
import re
pattern = 'n'
string = 'night'
prog = re.compile(pattern)
print(prog)
print(type(prog))
result = prog.match(string)
print(result)
print(type(result))
# 아래와 같이 생략 가능
result = re.match(pattern, string)
print(result)
print(type(result))
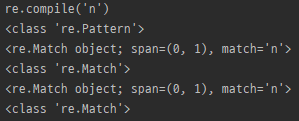
- 정규식 패턴을 정규식 객체로 컴파일
- 여러 정규식 객체를 재사용하는 것이 아니라면 위처럼 한번에 사용할 수 있음
- 정규식 객체는 아래 참조
re.search
import re
m = re.search('a', 'abcdef')
print(m)
m = re.search('b', 'abcdef')
print(m)
print(type(m))
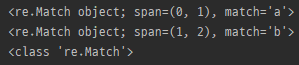
- string에서 pattern과 일치하는 첫 번쨰 위치를 찾고 일치 객체를 반환. (일치가 없으면 None)
- search()와 ' ^ '를 사용한 경우에는 각 줄의 시작 부분에서 일치
re.match
import re
m = re.match('a', 'abcdef')
print(m)
print(type(m))
m = re.match('b', 'abcdef')
print(m)
print(type(m))
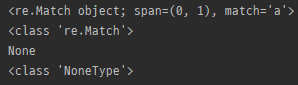
- 문자열의 처음부터 정규식 매칭
- 일치가 있는 경우 Match 객체를, 없을 경우 None을 반환
- MULTILINE 모드에서도 문자열의 시작 부분에서만 일치를 찾음 (무조건 문자열 시작에서)
re.fullmatch
import re
m = re.fullmatch('abc', 'abcdef')
print(m)
print(type(m))
m = re.match('abc', 'abc')
print(m)
print(type(m))
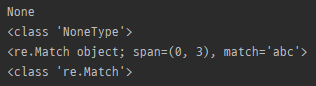
- 전체 string이 pattern과 일치할 경우 일치 객체 반환.
re.split
import re
string = 'Hello World!'
m = re.split('[ ]', string)
print(m)
print(type(m))
m = re.split('', string)
print(m)
print(type(m))
m = re.split('', string, maxsplit=3)
print(m)
print(type(m))
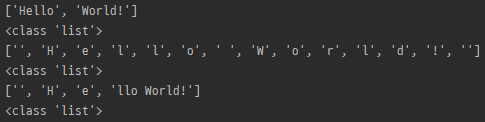
- string을 pattern 기준으로 나눔 (pattern은 list에 포함되지 않음)
- maxline이 0이 아닌경우 maxplit만큼 나누고, 남은 놈들은 한번에 처리 (총 maxsplit + 1 개가 List로 반환)
re.findall
import re
string = 'set width=20 and height=10'
m = re.findall('(\w+)=(\d+)', string)
print(m)
print(type(m))
m = re.findall('[as]..', string)
print(m)
print(type(m))
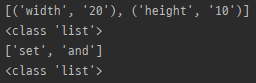
- 일치된는 모든 문자열을 리스트로 반환 (시작부터)
- pattern에 그룹이 있는 경우, 그룹에 해당하는 tuple의 list를 반환
re.finditer
import re
string = 'set width=20 and height=10'
m = re.finditer('(\w+)=(\d+)', string)
print(m)
print(type(m))
print()
for t in m:
print(t)
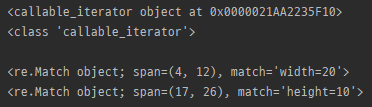
- findall과 같지만 일치 객체의 iterator를 반환
re.sub
import re
string = 'a1b2c3d4e5'
m = re.sub('\d', '-', string)
print(m)
m = re.sub('\d', '-', string, count=4)
print(m)
def repl (s):
print(s)
if s[0] == '1':
return ' ONE '
if s[0] == '2':
return ' TWO '
else:
return '-'
m = re.sub('\d', repl, string)
print(m)
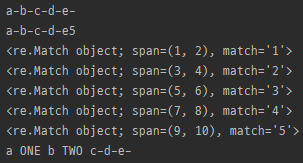
- string에서 pattern과 일치되는 것을 replace(repl)로 교체하고 string 반환
- replace는 string이 될 수도 있고, 함수일수도 있음
- 함수일 경우 전달되는 인자는 일치 객체
- count는 최대 몇번까지 교체할 것인가를 설정하는 인자.
re.subn
import re
string = 'a1b2c3d4e5'
m = re.subn('\d', '-', string)
print(m)
m = re.subn('\d', '-', string, count=4)
print(m)
def repl (s):
print(s)
if s[0] == '1':
return ' ONE '
if s[0] == '2':
return ' TWO '
else:
return '-'
m = re.subn('\d', repl, string)
print(m)
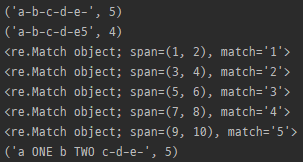
- subn()과 같지만 튜플을 반환
- (new_string, number_of_subs_made)
re.escape
import re
import string
m = re.escape('www.python.org')
print(m)
print(type(m))
str = string.ascii_lowercase + ' ' + string.digits
m = re.escape(str)
print(m)
print(type(m))
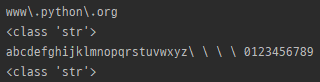
- string의 특수문자를 escape 처리 함
re.purge
- 정규식 캐시를 지움
정규식 객체
함수와 유사한 메서드
- search(string, pos, endpos)
- match(string, pos, endpos)
- fullmatch(string, pos, endpos)
- split(string, maxsplit)
- findall(string, pos, endpos)
- finditer(string, pos, endpos)
- sub(repl, string, count=0)
- subn(repl, string, count=0)
- 몇몇 메소드에서 pos 가 추가되고 flag 등이 빠진건 빼고는 유사함.
기타 메서드
- Pattern.flags : 정규식 일치 플래그 (compile()에 주어진 플래그)
- Pattern.group : 패턴에 있는 그룹 수
- Pattern.groupindex : (?P<id>)로 정의된 기호 그룹 이름을 그룹 번호에 매칭하는 딕셔더리
- Pattern.pattern : 패턴 객체가 컴파일된 패턴 문자열
일치 객체
match = re.search(pattern, string)
if match:
process(match)- 일치 객체는 항상 True 값을 가짐
- match()와 search()의 경우 일치가 없을 때 None을 반환하기 때문에 위와 같은 if문 사용 가능
Match.expand
import re
m = re.search(r'(\d\d\d\d)', 'in the year 1999')
print(m.expand(r"Year: \1"))
m = re.search(r'(?P<phone>\d{3}-\d{4}-\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m.expand(r'홍길동 HP : \g<phone>'))
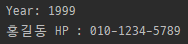
- template에 역슬래시 치환을 수행하여 얻은 문자열을 반환.
- '\n' 같은 이스케이프는 적절한 문자로, 숫자 역참조(\1, \2)와 이름 있는 역참조 (\g<name>
Match.group
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m.group)
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.group(3))
print()
print(m.group(0, 1))
print(m.group(0, 1, 2, 3))
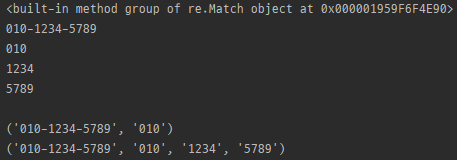
- group0 : 일치된 전체 문자열
- groupN(N>0) : 일치된 문자열의 N번째 그룹
- 괄호 안에 여러 숫자를 넣을 경우 tuple 형태로 반환
Match.__getitem__
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m)
print(m[0])
print(m[1])
print(m[2])
print(m[3])
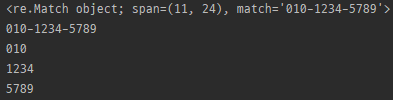
- Match.group(g)와 같음
Match.groups
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m.groups())
print(m.groups()[0])
print(m.groups()[1])
print(m.groups()[2])
m = re.search(r'(\d{3})-?(\d{4})?-?(\d{4})?', '홍길동의 전화번호는 010-123-456 입니다.')
print(m.groups())
print(m.groups('0'))
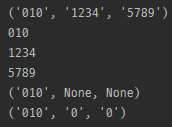
- groups()의 경우 모든 group의 값이 tuple의 형태로 반환
- 괄호 안에 값을 넣어주면 deafult 값이 None에서 해당 값으로 바뀜 (?등을 이용해 값이 선택적인 경우)
Match.groupdict
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m.groupdict())
m = re.search(
r'(?P<first>\d{3})-(?P<second>\d{4})-(?P<third>\d{4})',
'홍길동의 전화번호는 010-1234-5678 입니다.'
)
print(m.groupdict())

- 그룹의 이름을 Key로, 값을 value로 하는 Dictionary 반환
- 이름이 있는 경우만.. 없는 \1, \2 등은 포함되지 않음
Match.start
import re
m = re.search(r'python', 'I love python so much')
print(type(m.start()))
print(m.start())
print(m.start(0))
m = re.search(r'(python)?', 'I love javascript so much')
print(type(m.start()))
print(m.start())
print(m.start(0))
print(m.start(1))
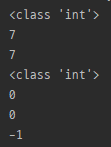
- 일치된 문자열의 시작 위치 반환
- 선택적(? 사용) 일 경우, 해당 그룹의 일치가 없으면 -1 반환
- 전체 일치가 없으면 0 반환
- Match.start(0)는 Match.start()와 같음 (기본값 0)
Match.end
import re
m = re.search(r'python', 'I love python so much')
print(type(m.end()))
print(m.end())
print(m.end(0))
m = re.search(r'(python)?', 'I love javascript so much')
print(type(m.end()))
print(m.end())
print(m.end(0))
print(m.end(1))
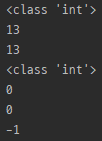
- 일치된 문자열의 종료 위치 반환 (정확히는 끝지점 +1)
- 선택적(? 사용) 일 경우, 해당 그룹의 일치가 없으면 -1 반환
- 전체 일치가 없으면 0 반환
- Match.end(0)는 Match.end()와 같음 (기본값 0)
Match.span
import re
m = re.search(r'python', 'I love python so much')
print(type(m.span()))
print(m.span())
print(m.span(0))
m = re.search(r'(python)?', 'I love javascript so much')
print(type(m.span()))
print(m.span())
print(m.span(0))
print(m.span(1))
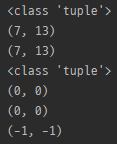
- start와 end를 tuple로 반환
- span(0)은 span()와 같음
Match.pos
import re
p = re.compile(r'python')
m = p.search('I love python so much', 5, 15)
print(type(m.pos))
print(m.pos)
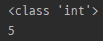
- 괄호 없이 (메서드가 아니기 때문)
- Pattern.search나 Pattern.match에 넘겨준 pos 값 반환
- re.search 나 re.match는 pos 값 없음
Match.endpos
import re
p = re.compile(r'python')
m = p.search('I love python so much', 5, 15)
print(type(m.endpos))
print(m.endpos)
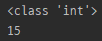
- 괄호 없이 (메서드가 아니기 때문)
- Pattern.search나 Pattern.match에 넘겨준 endpos 값 반환
- re.search 나 re.match는 endpos 값 없음
Match.lastindex
import re
m = re.search('(a)b', 'ab')
print(m.lastindex)
m = re.search('(ab)', 'ab')
print(m.lastindex)
m = re.search('a(b)', 'ab')
print(m.lastindex)
m = re.search('(a)(b)', 'ab')
print(m.lastindex)
m = re.search('ab', 'ab')
print(m.lastindex)
m = re.search('(ab)?c', 'cde')
print(m.lastindex)
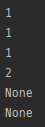
- 마지막으로 일치된 그룹의 인덱스. (1부터 시작)
- 그룹이 없으거나 일치가 없으면 None 반환
Match.lastgroup
import re
m = re.search('(ab)', 'ab')
print(type(m.lastgroup))
print(m.lastgroup)
m = re.search('(?P<name1>a)(?P<name2>b)', 'ab')
print(m.lastgroup)
m = re.search('(?P<name>a)b', 'ab')
print(m.lastgroup)
m = re.search('(?P<name>ab)?c', 'cde')
print(m.lastgroup)
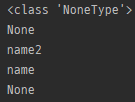
- 마지막으로 일치된 그룹의 이름 반환
- 이름이 정해진 그룹이 없거나 일치가 없으면 None 반환
- 반환되는 형태는 str이 아님
Match.re
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(m.re)
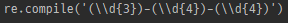
- match나 search가 생성한 정규식 개체 반환
Match.string
import re
m = re.search(r'(\d{3})-(\d{4})-(\d{4})', '홍길동의 전화번호는 010-1234-5789 입니다.')
print(type(m.string))
print(m.string)

- str 형태로 match나 search에 전달된 문자열 반환
참조
- 파이썬 공식문서
- 점프 투 파이썬
- 토닥토닥 파이썬 - 데이터 수집 (비정형 데이터)
'Languages > Python' 카테고리의 다른 글
| [파이썬 101] lambda (람다) (0) | 2022.06.03 |
|---|---|
| [파이썬 101] map 함수 (Iterator, Iterable) (0) | 2022.06.03 |
| [파이썬 101] 정규표현식 (0) | 2022.05.30 |
| [파이썬 101] 문자열 매칭 메소드 (in, find, rfind, index, rindex startswith, endswith) (0) | 2022.05.28 |
| [파이썬 101] zip() (0) | 2022.05.24 |



