728x90

0. 파이썬의 컨테이너
| 컨테이너 | 기호 | 설명 | 예시 |
| List | [ ] 대괄호 | - 배열과 비슷한 객체 - 함수가 존재 - 인덱스 값을 이용한 접근이 가능 |
a = list() b = [] c = [1, 2, 3, 'dog', ['Hello', 'World']] d = range(10) #0부터 차례대로 리스트 |
| Dictionary | { } 중괄호 | - Key, Value 쌍으로 저장 - Key 값은 고유해야함 - 정보를 빠르게 찾을 수 있음 - 메모리를 많이 차지함 |
a = {'name':'pey', 'phone':'0119993323'} b = {1: 'hello', 2: 'world'} c = {'a' : [1,2,3]} |
| Set (집합) | { } 중괄호 | - 순서 구분이 없음 - 중복을 허용하지 않음 - 수학에서의 집합과 비슷한 개념 |
a = set() b = set([1, 2, 3]) c = {a, b, c} |
| Tuple | ( ) 소괄호 | - 변경할 수 없음(추가, 삭제 등..) - 리스트와 유사 |
a = () b = (1, 2, 3) c = 1, 2, 3 d = ('a', 'b', ('c', 'd')) |
1-1. List의 성질
# 선언
list_a = list()
#list_b = list(1, 2, 3)
list_c = [1, 2, 3, 'dog', ['Hello', 'World']]
list_d = range(10)
print(list_a)
#print(list_b)
print(list_c)
print(list_d)
print(list_d[3])
# 연산
my_list_1 = [1, 2, 3]
my_list_2 = ['a', 'b', 'c']
print(my_list_1 + my_list_2)
print(my_list_1 * 3)

- list() 괄호 안에 요소를 넣어서 선언할 수 없음
- range()로 만들 경우 range 객체(?)로 되어 list 함수 사용할 수 없음
- 다중 리스트는 c의 n차원 배열처럼 인덱싱할 수 있음
1-2. List 관련 함수
| 용법 | 설명 |
| {리스트명}.index(x[, start[, end]]) | start와 end 사이에서 x 값을 가지는 인덱스를 반환 |
| {리스트명}.count(x) | 리스트에 포함된 요소 x의 개수 세기 |
| {리스트명}.extend(iterable) | 리스트 끝에 여러 항목을 추가 |
| {리스트명}.append(x) | 리스트 끝에 항목(x) 하나 추가 |
| {리스트명}.insert(i, x) | 인덱스 i의 위치에 x 삽입 |
| {리스트명}.sort() | 알파벳 숫서 / 숫자 크기로 정렬 (오름차순) |
| {리스트명}.reverse() | 알파벳 순서 / 숫자 크기로 정렬 (내림차순) |
| {리스트명}.remove(x) | x값을 삭제 (없으면 ValueError) |
| del {리스트명}[x] | 인덱스가 x인 항목 삭제 |
| {리스트명}.pop() | 리스트 마지막 항목을 삭제하고 값을 return |
| {리스트명}.pop(x) | 해당 인덱스(x)의 항목을 삭제하고 값을 return |
| {리스트명}.clear() | 리스트의 모든 항목 삭제 |
| {리스트명}.copy() | 리스트 얕은복사해서 반환 |
1-3. List 슬라이싱
| 슬라이싱 | 설명 |
| [a:b] | a 인덱스부터 b-1 까지 |
| [:] | 전체 List |
| [:b] | 0 부터 b-1 까지 |
| [a:] | b 부터 끝까지 |
| [:-c] | 처음부터 [-c-1] 까지 |
| list[i:j] = t | i 부터 j 까지를 t로 바꿈 (t 는 iterable) |
| list[i:j:k] = t | 이터러블 t의 값으로 바꿈 (길이가 같아야 함) |
| list[i:j:k] | i 부터 j 까지 k 만큼 건너뛰며 |
| list[i:i] = [x] | list.insert(i, x) 와 동일 ( list를 추가할 수도 있음) |
1-4. List와 enumerate
my_list = ['a', 'b', 'c']
for idx, member in enumerate(my_list):
print('%d %s' %(idx, member))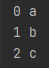
2-1. Dictionary의 선언
dict_a = {1: 'a', 2: 'b', 3: ['c', 'd']}
dict_b = {1: 'a', 1: 'b'}
print(dict_a)
print(dict_b)
my_list = [1, 2, 3, 4, 5]
my_dict_1 = {i: i for i in my_list}
print(my_dict_1, end='\n\n')
my_dict_2 = {i: i * 2 for i in my_list}
print(my_dict_2, end='\n\n')
my_dict_3 = {i: i * 2 for i in my_list if i % 2 == 1}
print(my_dict_3)

- Value에는 다양한 값을 넣을 수 있음
- Key가 겹칠 경우 덮어쓰기 됨
- Key에는 튜플이 사용될 수 있음
- Value에는 다양한 객체 사용 가능
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
a == b == c == d == e #True- Tuple로 key-value 쌍 표현 가능
2-2. Dictionary 관련 함수
| 용법 | 설명 |
| {딕셔너리명}[key] = value | 새로운 Key-value 추가 |
| {딕셔너리명}.keys() | 모든 Key를 리스트로 반환 |
| {딕셔너리명}.values() | 모든 Value를 리스트로 반환 |
| key in {딕셔너리명} | 해당 Key가 딕셔너리에 존재하는지 여부 |
| del {딕셔너리명}[value] | 해당 Key-Value 쌍 삭제 |
| {딕셔너리명}.clear() | 모든 Key-Value 삭제 |
| {딕셔너리명}.get(key[, default]) | key에 해당하는 Value 반환. 없으면 deafult 반환 (default가 없으면 None 반환) |
| iter(d) | iter(d.keys())와 동일 |
| {딕셔너리명}.clear() | 모든 항목 삭제 |
| fromKeys(iterable[, value]) | iterable에서 Key 값을, value는 value로 하는 새로운 디셔너리 반환 |
| {딕셔너리명}.items() | (key, value)의 view 반환 |
| {딕셔너리명}.pop(key[, default]) | key가 존재하면 삭제하고 반환. 없으면 default (default가 없으면 KeyError 반환) |
| {딕셔너리명}.popitem() | LIFO로(스택과 동일) (key, value) 반환. 비어있으면 KeyError |
| {딕셔너리명}.setdeault(key[, default]) | key에 해당하는 value를 반환. 없으면 deault 반환 |
| {딕셔너리명}.update([other]) | other가 제공하는 key-value 쌍을 추가. 키존에 있는 키를 덮어씀. None 반환 |
2-3. Dictionary와 for 문
my_dict = {'c': 3, 'b': 2, 'a': 1}
# Key가 들어감
for letter in my_dict:
print(letter)
print()
# sorted() 사용
for letter in sorted(my_dict.keys()):
print(letter)
print()
# items() 사용
for letter, number in my_dict.items():
print(letter, number)
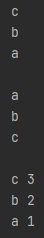
3-1. Set의 특징
- set 객체는 인덱싱을 지원하지 않음 (my_index[n]으로 접근 불가)
- 선언시 중복되는 값을 넣어도 set에는 하나만 저장됨
- sort를 지원하지 않음 (순서가 없으니 당연)
3-2. Set 관련 함수
| 용법 | 설명 |
| {집합명}.add(x) | x 추가 |
| {집합명}.update(set) | 기존 데이터에 set 추가 (합집합) |
| {집합명}.remove(x) | x 삭제 (없으면 KeyError) |
| {집합명}.isdisjoint(other) | other와 공통원소를 갖으면 True, 없으면 False |
| {집합명}.issubset(other) | other의 부분집합이면 True, 아니면 False |
| {집합명}.issuperset(other) | other가 확대집합이면 True, 아니면 False |
| {집합명}.copy() | 얕은 복사본 반환 |
| {집합명}.union(*other) | 합집합 반환 |
| {집합명}.intersection(*others) | 교집합 반환 |
| {집합명}.difference(*others) | set - other (차집합) 반환 |
| {집합명}.symetric_difference(*others) | 합집합 - 교집합 반환 |
| {집합명}.intersection_update(*others) | 합집합으로 변경 |
| {집합명}.difference_update(*others) | 차집합으로 변경 |
| {집합명}.symetric_difference_update(*others) | 합집합 - 교집합 으로 변경 |
| {집합명}.discard(elem) | elem이 있으면 삭제 |
| {집합명}.pop() | 임의의 원소를 제거하여 반환 (공집합이면 KeyError) |
| {집합명}.clear() | 모든 원소 제거 |
3-3 Set 연산
| 연산 | 설명 |
| set <= other | set가 other의 부분집합인지 확인 |
| set < other | set가 other의 진부분집합인지 확인 |
| set >= other | other가 set의 부분집합인지 확인 |
| set > other | other가 set의 진부분집합인지 확인 |
| set | other | ... | 합집합 (set |= other 사용 가능) |
| set & other & ... | 교집합 (set &= other 사용 가능) |
| set - other - ... | 차집합 (set -= other 사용 가능) |
| set ^ other | 합집합 - 교집합 (set ^= other 사용 가능) |
3-4. Set 생성하는 방법
my_list = [1, 2, 3, 4, 5]
my_set_1 = {i for i in my_list}
print(my_set_1, end='\n\n')
my_set_2 = {i * 2 for i in my_list}
print(my_set_2, end='\n\n')
my_set_3 = {i * 2 for i in my_list if i % 2 == 1}
print(my_set_3, end='\n\n')
my_set_4 = set('Hello World!')
print(my_set_4, end='\n\n')
my_set_5 = set(my_list)
print(my_set_5)

- 인덱싱이 불가하므로 인덱싱이 필요할 경우 List나 Tuple로 변환하여함 (Set은 순서가 없는 자료형이기 때문)
3-5. Set와 enumerate
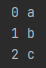
my_set = {'a', 'b', 'c'}
for idx, letter in enumerate(my_set):
print('%d %s' %(idx, letter))
3-5. Set 집합 연산
my_set_1 = {1, 2, 3, 4, 5, 6, 7}
my_set_2 = {3, 4, 5, 6, 7, 8, 9}
# 교집합
print(my_set_1 & my_set_2)
# 합집합
print(my_set_1 | my_set_2)
# 차집합
print(my_set_1 - my_set_2)
print(my_set_2 - my_set_1)
print(my_set_1.difference(my_set_2))
print(my_set_2.difference(my_set_1))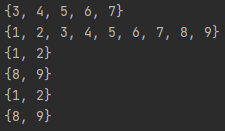
- 교집합, 합집합, 차집합 구할 수 있음
- difference 사용해서 차집합 구할 수 있음
4-1. Tuple
# 선언
my_tuple_1 = (1, 2, 3, 4, 5, ('a', 'b', 'c'))
print(my_tuple_1, end='\n\n')
my_tuple_2 = 1, 2, 3, 4, 5
print(my_tuple_2, end='\n\n')
# dictionary에 사용
my_dict = {(i, i * 2, i * 3): [i, i * 4, i * 5] for i in range(5)}
print(my_dict)

- tuple은 딕셔너리의 Key나 Value나로 사용될 수 있음
- tuple 안에 list를 요소로 넣을 수 없음
- tuple 안에 tuple을 넣을 수 있음
- tuple에 del이나 할당 연산자(=)를 사용하여 값을 수정하거나 삭제할 수 없음
4-2. Tuple의 성질
my_tuple_1 = ('a', 'b', 'c', 'd', 'e')
my_tuple_2 = (1, 2, 3, 4, 5)
print(my_tuple_1[1])
print(my_tuple_1[2:-1])
print(my_tuple_1 + my_tuple_2)
print(my_tuple_1 * 3)

- 인덱싱 가능
- 슬라이싱 가능
- '+' 연산자로 두개의 튜플 합치기 가능
- '*' 연산자로 튜플 반복 가능
참조
- 파이썬 공식문서
- 멕스웰과 데자와 블로그
- 점프 투 파이썬
반응형
'Languages > Python' 카테고리의 다른 글
| [파이썬 101] 정규표현식 (0) | 2022.05.30 |
|---|---|
| [파이썬 101] 문자열 매칭 메소드 (in, find, rfind, index, rindex startswith, endswith) (0) | 2022.05.28 |
| [파이썬 101] zip() (0) | 2022.05.24 |
| [파이썬 101] 해시(Hash) (0) | 2022.05.24 |
| [파이썬 라이브러리] Collections 모듈의 Counter 클래스 (0) | 2022.05.23 |



